Numerically minimising Pauli-weight#
One frequently cited goal when designing an encoding \(\mathcal{E}\) is to minimise the average number of Pauli-operators in the terms of the qubit Hamiltonian. This measure is known as the Pauli-weight of the Hamiltonian.
This might make you think that we should try to find an encoding which minimises the Pauli-weight of indiviaul fermionic operators, for ternary tree encodings, we can show the JKMN encoding gives the minimal average Pauli-weight for fermionic operators. However, often we want to represent terms of a specific Hamiltonian, which contain more than on operator. The product of two operators with high Pauli-weight might have a low Pauli-weight!
Defining Pauli-weight#
Consider the set of majorana operators \(\set{\gamma}\). With \(P(x)\) being the Pauli-weight of \(x\),
If we have a specific Hamiltonian in mind, say the electronic structure hamiltonian,
we can define the Pauli weight the set of Hamiltonian terms \(\{h\}\) which result from encoding terms of the fermionic Hamiltonian (\(a_i^{\dagger}a_j\) and \(a_i^{\dagger}a_j^{\dagger}a_k a_l\)). Note that we don’t need to consider the Hamiltonian coefficents \(\{\alpha_{i,j}, \alpha_{i,j,k,l}\}\) associated to each of those operators, so this Pauli-weight is system independent.
When considering a real system (such as a water molecule), many of the terms of the fermionic Hamiltonian will represent transitions which are not allowed. As a result, some terms of the general qubit Hamiltonian will not be needed.
This isn’t the end of the story however, because the specific set of qubit operator terms which have non-zero coefficients depends on which operators in the encoding represent which fermionic operators (an enumeration_scheme). Accounting for this, we have the system dependent Pauli-weight:
First we’ll import data we need specific to the water molecule.
import json
import numpy as np
import ferrmion as fr
import matplotlib.pyplot as plt
from pathlib import Path
def integrals():
folder = Path.cwd().joinpath(Path("../../../python/tests/"))
with open(folder.joinpath("./data/h2o_6-31g.json"), "rb") as file:
data = json.load(file)
return np.array(data["ones"]), np.array(data["twos"])
ones, twos = integrals()
n_modes = ones.shape[0]
tree = fr.TernaryTree(n_modes)
encodings: dict[str, fr.MajoranaEncoding] = {
"jw":fr.JordanWigner(n_modes),
"pe":fr.Parity(n_modes),
"bk":fr.BravyiKitaev(n_modes),
"jkmn":fr.JKMN(n_modes),
"MaxNTO":fr.MaxNTO(n_modes)
}
for k,v in encodings.items():
if isinstance(v, fr.TernaryTree):
v.build_encoding()
encodings[k] = v._encoding
def plot_ps(distributions, *, naive=None, annealed_weight=None, topphatt_weight=None):
fig, axs = plt.subplots()
pos = {name: pos for pos,name in enumerate(encodings.keys())}
for name, dist in distributions.items():
axs.violinplot(dist, [pos[name]])
axs.set_xticks([*range(len(encodings))], labels=[*encodings.keys()])
for name in encodings:
if naive:
axs.hlines(naive[name], pos[name] - 0.25, pos[name] + 0.25, linestyles=":", color="black")
if annealed_weight:
axs.hlines(
annealed_weight[name],
pos[name] - 0.25,
pos[name] + 0.25,
linestyles="-.",
color="black",
)
if name == "MaxNTO":
continue
if topphatt_weight:
axs.hlines(
topphatt_weight[name],
pos[name] - 0.25,
pos[name] + 0.25,
linestyles="--",
color="black",
)
handles = []
if naive:
naive_line = mlines.Line2D(
[], [], color="black", linestyle=":", label="Naive Enumeration"
)
handles.append(naive_line)
if annealed_weight:
anneal_line = mlines.Line2D(
[], [], color="black", linestyle="-.", label="Simulated Annealing"
)
handles.append(anneal_line)
if topphatt_weight:
topphatt_line = mlines.Line2D([], [], color="black", linestyle="--", label="TOPP-HATT")
handles.append(topphatt_line)
axs.legend(handles=handles)
plt.title("$P_S$ Weight of $H_2O$ (STO-3G)")
plt.show()
\(P_{E}\)#
import numpy as np
def encoding_weight(encoding: fr.MajoranaEncoding):
if isinstance(encoding, fr.TernaryTree):
encoding.build_encoding()
encoding = encoding._encoding
symplectics = encoding.symplectic_matrix
x_block, z_block = np.hsplit(symplectics, 2)
operator_weights = np.sum(np.bitwise_or(x_block, z_block), axis=1)
return operator_weights
ham_indep = {name: encoding_weight(encoding) for name, encoding in encodings.items()}
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
fig, axs = plt.subplots()
pos = 0
for dist in ham_indep.values():
axs.violinplot(dist, [pos], showmeans=True)
pos += 1
axs.set_xticks([*range(len(ham_indep))], labels=ham_indep.keys())
plt.title("Weight of Encoding Strings")
plt.show()
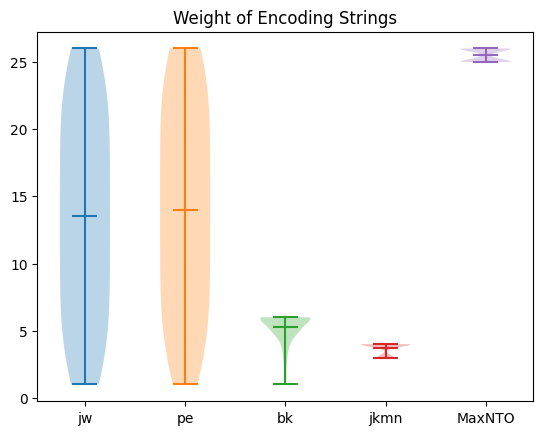
So it seems there is a clear benefit to the multi-branch Bravyi-kitaev and JKMN (minimum height) trees!
Let’s move on to see how these encodings behave when applied to the electronic structure Hamiltonian.
\(P_{H}\)#
We can find the hamiltonian weight by setting every term of the hamiltonian to 1, so that all the terms are included, and able to cancel eachother out.
import numpy as np
def hamiltonian_term_weights(encoding: fr.MajoranaEncoding, hamiltonian: fr.FermionHamiltonian):
if isinstance(encoding, fr.TernaryTree):
encoding.build_encoding()
encoding = encoding._encoding
weights = []
for i in range(hamiltonian.n_modes):
for j in range(i, hamiltonian.n_modes):
# Process each term in the Hamiltonian
pterm = encoding.encode_fermion_product("+-", [i,j],1)
weights.append(pterm.pauli_weight())
for k in range(j, hamiltonian.n_modes):
for l in range(k, hamiltonian.n_modes):
pterm = encoding.encode_fermion_product("++--", [i,j,k,l],1)
weights.append(pterm.pauli_weight())
return np.array(weights)
ones, twos = np.ones((n_modes, n_modes)), np.ones((n_modes, n_modes, n_modes, n_modes))
fham = fr.molecular_hamiltonian(ones, twos, physicist_notation=True)
ham_dep = {
name: hamiltonian_term_weights(encoding, fham)
for name, encoding in encodings.items()
}
import matplotlib.pyplot as plt
fig, axs = plt.subplots(2, 1, sharex=True, sharey=False)
pos = 0
for k in ham_dep.keys():
axs[0].violinplot(ham_indep[k], [pos], showmeans=True)
axs[1].violinplot(ham_dep[k], [pos], showmeans=True)
pos += 1
axs[0].title.set_text("Weight of Encoding Strings")
axs[1].title.set_text("Weight of Hamiltonian Terms")
axs[1].set_xticks([*range(len(ham_dep))], labels=ham_dep.keys())
plt.show()
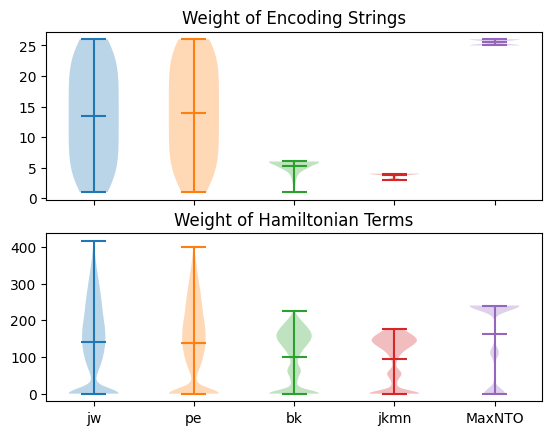
How interesting! The Bravyi-Kitaev and JKMN encodings have lost a lot of their advantage now that we’re considering the application of encodings to Hamiltonian terms.
Conversely, the k-NTO encoding now performs much more similarly to the ternary trees.
For a specific fermionic system, say a water molecule, some of the hamiltonian coefficients will be zero, and others might cancel eachother out after they have been encoded as Pauli operators.
Since we can give any labels we want to fermionic modes (molecular orbitals of water), it might be possible to assign these so that out hamiltonian terms have the lowest possible Pauli-weight.
\(P_{S}\)#
Let’s start by finding \(P_{S}\) for a set of random permutations of the fermionic mode labels.
We’ll run each encoding with 250 different enumerations of the fermionic modes. We can generate random permutations and pass them to .batch_pauli_weights, which returns both the Pauli-weight and coefficient Pauli-weight together.
ones, twos = integrals()
fham = fr.molecular_hamiltonian(ones, twos, physicist_notation=True)
rng = np.random.default_rng(0)
permutations = rng.permuted(
np.tile(np.arange(n_modes, dtype=np.uintp), (250, 1)), axis=1
)
distributions = {
name: encoding.batch_pauli_weights(fham, permutations)[0]
for name, encoding in encodings.items()
}
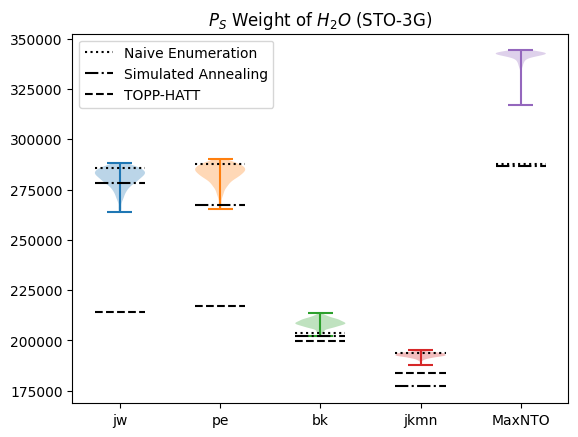
plot_ps(distributions)
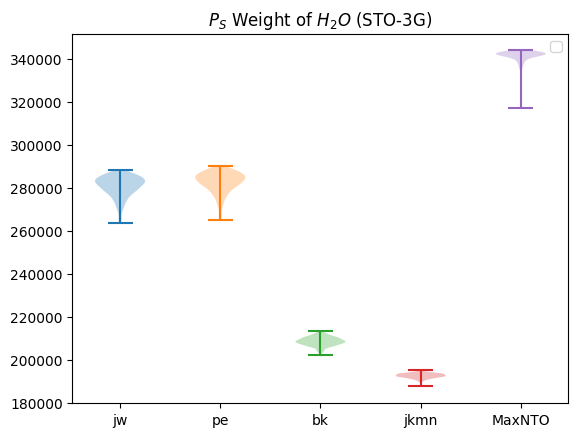
It looks like \(P_S\) varies quite a lot depending on the enumeration scheme we use.
Optimising \(P_S\)#
Since we’ve seen that the enumeration scheme can have an effect on the Pauli-weight, we coudl try to optimise this to get a lower Pauli-weight. This should make our quantum circuits smaller and therefore more accurate!
First, let’s find the weight of the naive enumerations, the standard form of the encodings as they were first developed.
naive = {}
for name, encoding in encodings.items():
if isinstance(encoding, fr.TernaryTree):
encoding.build_encoding()
encoding = encoding._encoding
naive[name] = encoding.encode(fham).pauli_weight()
plot_ps(distributions, naive=naive)
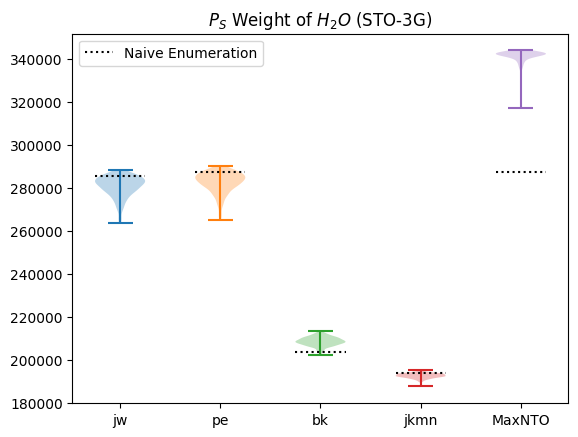
For the Ternary Tree encodings (Jordan-Wigner, Parity, Bravyi-Kitaev andJKMN), the naive enumeration seems to generally be one of the worst options. Interestingly, the naive enumeration is by far the best ofr MaxNTO.
Let’s try a numerical approach to optimise these, and see if we can get better values for the ternary trees.
Simulated Annealing#
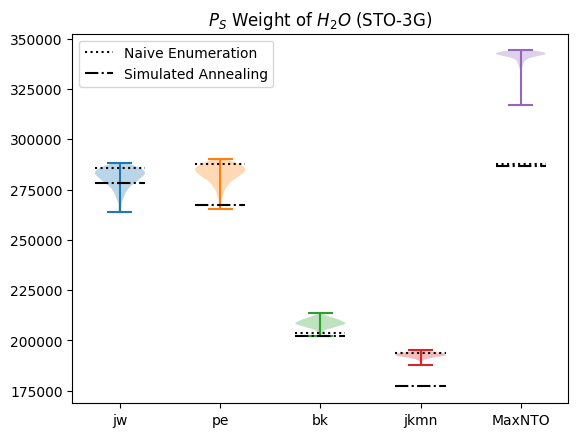
First, let’s try optimising all of these with simualted annealing.
Note we’re annealing to minimise the Pauli-weight. If you’re ineterested, try adding the coefficient_weighted=True flag below to see what happens when we minimise the coefficient scaled Pauli-weight.
annealed_weight = {}
for name, encoding in encodings.items():
print(f"Annealing {name.upper()}")
annealed_weight[name] = encoding.encode_annealed(fham).pauli_weight()
annealed_weight
Annealing JW
Annealing PE
Annealing BK
Annealing JKMN
Annealing MAXNTO
{'jw': 278064, 'pe': 267214, 'bk': 202165, 'jkmn': 177154, 'MaxNTO': 286880}
plot_ps(distributions, naive=naive, annealed_weight=annealed_weight)
TOPP-HATT#
For ternary-trees, we can apply the Topology-Preserving Hamiltonian-Adaptive Ternary Tree (TOPP-HATT) method to reduce the Pauli-weight.
Note this doesn’t work for the MaxNTO encoding, which is not based on a ternary tree data structure.
trees = {
"jw": fr.JordanWigner(n_modes),
"pe": fr.Parity(n_modes),
"bk": fr.BravyiKitaev(n_modes),
"jkmn": fr.JKMN(n_modes),
"MaxNTO": None, # MaxNTO is not based on a ternary tree
}
topphatt_weight = {}
for name, tree in trees.items():
if tree is not None:
topphatt_weight[name] = tree.encode(fham).pauli_weight()
else:
topphatt_weight[name] = None
plot_ps(distributions, naive=naive, annealed_weight=annealed_weight, topphatt_weight=topphatt_weight)